Don't Count Your Chickens Before Your Credentials
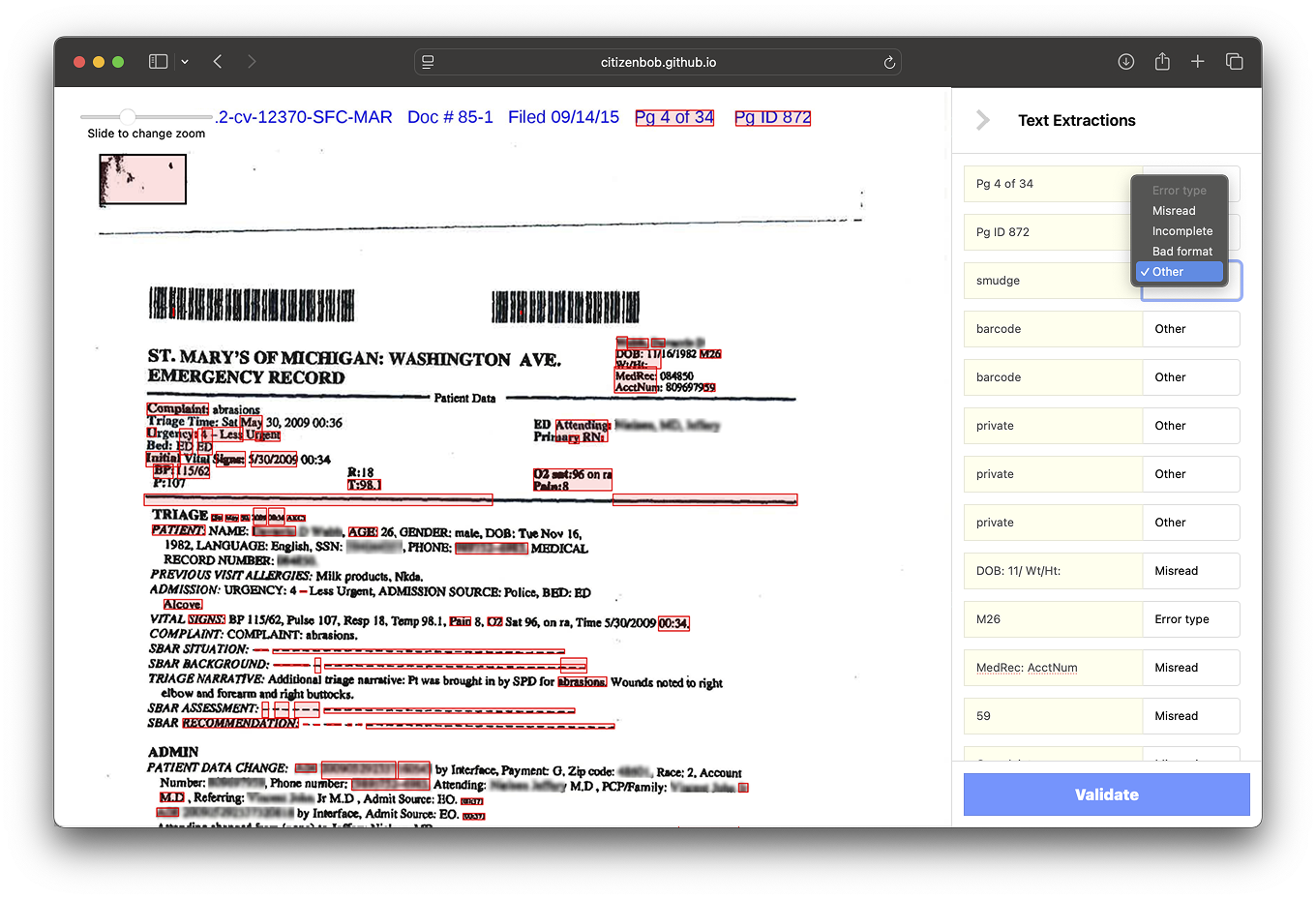
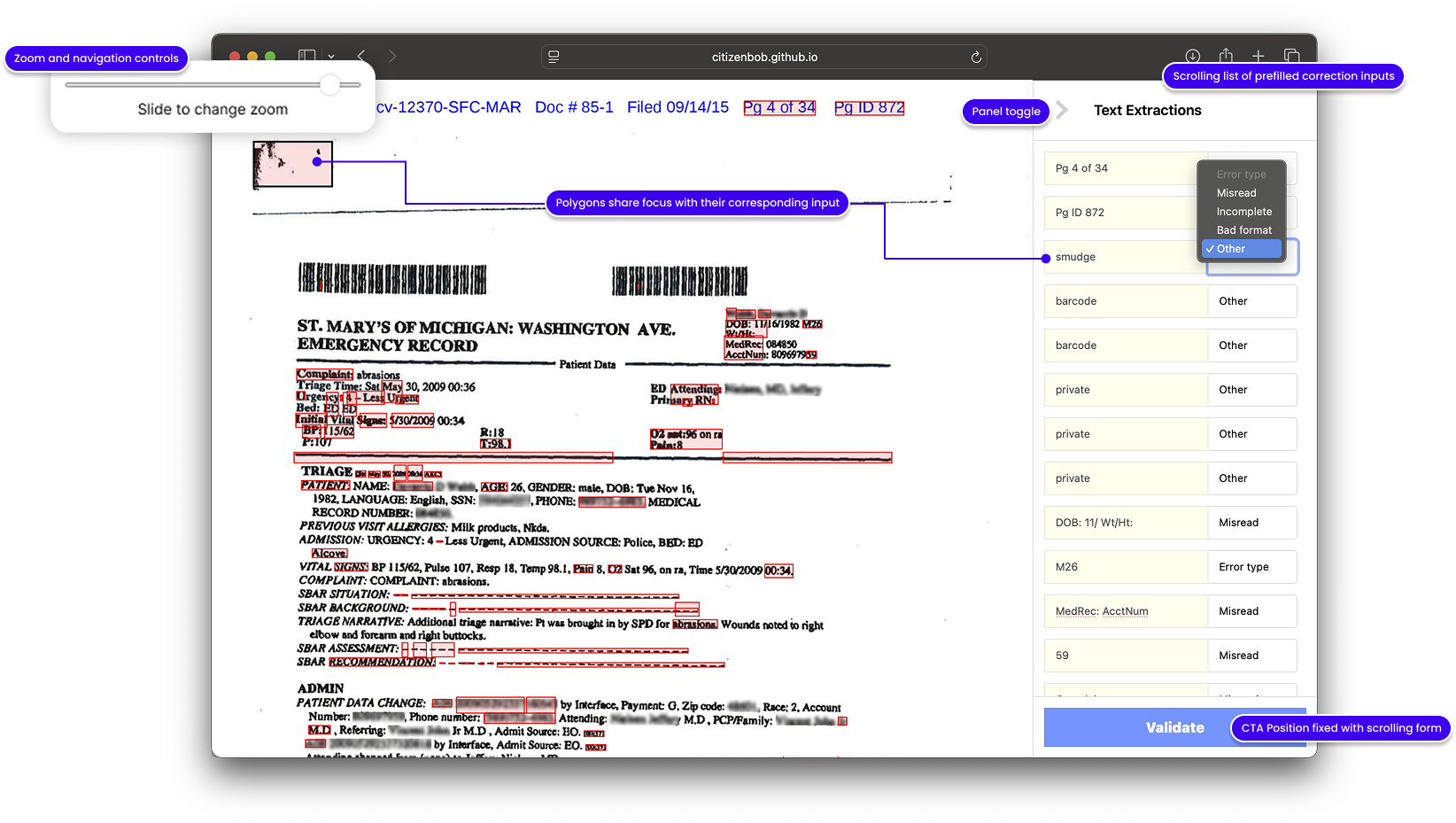
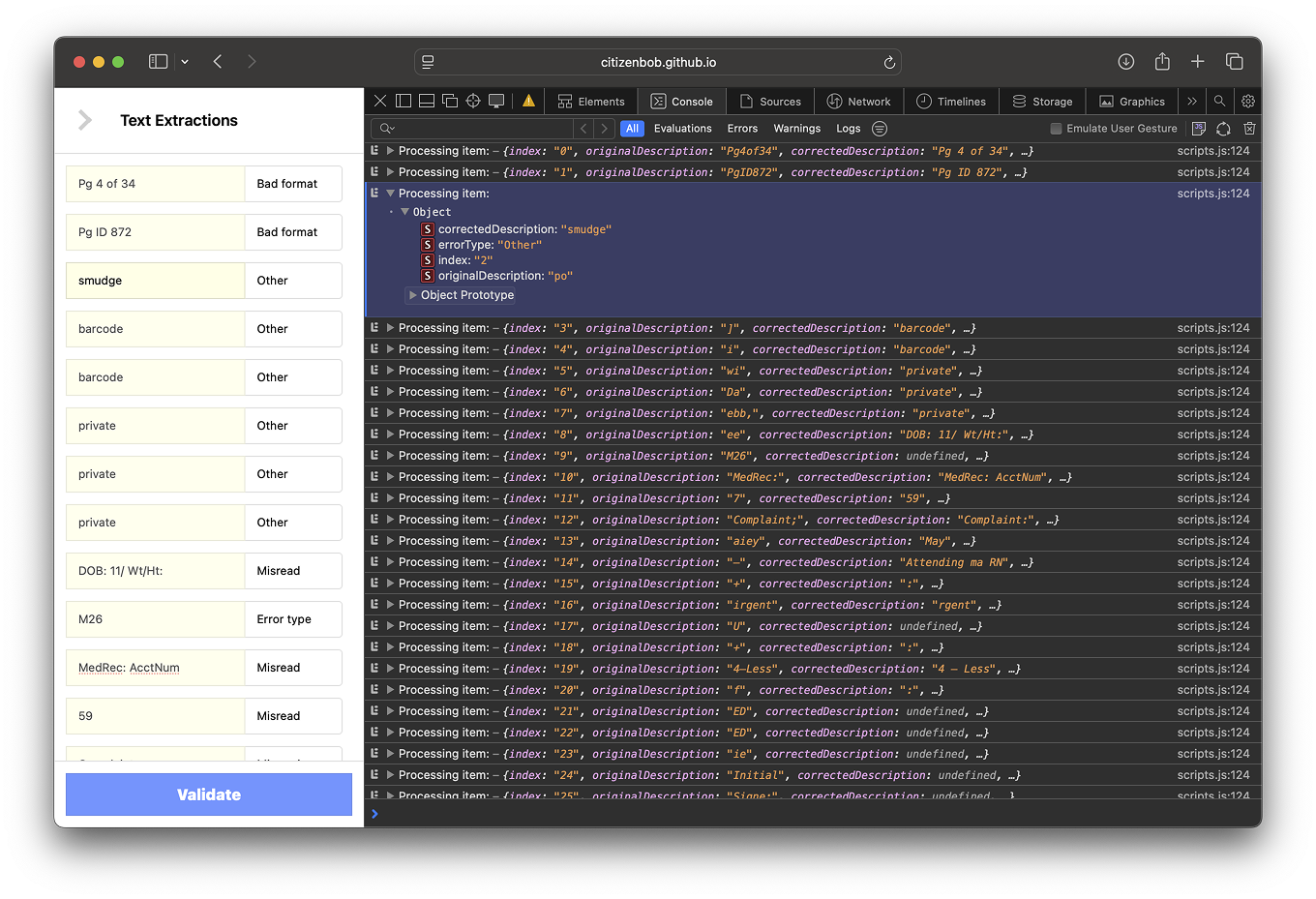
Our human-in-the-loop approach underscored that technology must augment, not replace, expert work. By involving paralegals in both design and model training, we produced high-quality data that improved model performance. Clear hypotheses and measurable goals kept the project focused.
The biggest surprise came after success: no one had agreed on who owned it. The data was better, the model smarter, the workflow proven—but the moment it worked, the questions started. Who controls the corrections? Who gets to use the output in production? Who signs off on the retraining loop?
Without shared credentials—legal or technical—the project stalled. Not because of failure, but because of ambiguity. It turns out, validating the model is only half the battle. The rest is validating the relationships around it.